Chess Artificial Intelligence
This artificial intelligence uses the UCI protocol and the following optimizations have been implemented:
- principal variation splitting (distributed algorithm)
- depth limited minimax with fail-soft alpha-beta pruning
- material evaluation
- tapered evaluation
- piece square tables
- transposition table
- quiescense search
- move ordering
- opening book (20 000 games)
It was made in collaboration with Justin Aubin for a course in Artificial Intelligence at UQAC and thanks to it we won the competition organized among students of the class.
Acknowledgements
The development of this intelligent agent was greatly facilitated by the previous work of Ben-Huer Carlos Viera Langoni Junior who developed the Java library chesslib. This library includes all the basic functions for the management of a chess game and allowed us to ignore this part during the development. In this way, we could concentrate our efforts on artificial intelligence.
Moreover, the site Chess Programming Wiki helped us a lot in the choice of the optimizations to implement because it lists in an almost exhaustive way all the existing techniques.
Principal-Variation-Splitting (PVS)
Our main optimization to improve the speed of tree exploration was to run it in parallel. Indeed, although Alpha-Beta pruning seems to be a sequential algorithm, it is possible to parallelize it if we make some concessions.
Let’s take the figure below as a basis. To do this, we will start by dividing the subtrees into two groups: The leftmost subtree (LeftSideNode) and all its brothers (Nodes). Then, we will move to the leftmost branch. For each level of our tree, we will iterate our process. When we arrive at the bottom of our tree, we give a single process the task of evaluating the leftmost node (LeftSideNode). This evaluation will provide a basis for our pruning. From there, it is possible to parallelize the sister nodes (Node) level by level. We will then give threads the task to perform the Alpha Beta algorithm initialized with the values of the leftmost node (LeftSideNode). Each thread will then send its result to its parent node which will be used as a basis for the parallelization of the upper stage.
![Principal Variation Splitting [1]](/assets/img/portfolio/chess_ai/PVS.png)
Finally, we realize that we lose the “optimality” in the number of nodes of the Alpha Beta pruning because the alpha and beta values are not updated globally for all the nodes but only at the end of the evaluation of the nodes of a same sibling. We will therefore evaluate more nodes than for the sequential Alpha Beta algorithm, which should slow down the process. Nevertheless, the fact of performing the exploration of the tree in parallel improves the performance (in this case the execution time). There are however two conditions to optimize this performance gain. The first condition (common with Sequential Alpha Beta) is to sort the nodes so that the first node is theoretically the most interesting and therefore prunes our tree faster (see Optimizations). The second condition concerns the size of the tree. Indeed, if we take a tree that is too small, the performance gains are less because the creation of a thread pool is a relatively time consuming process. In our program we consider that the first gains are made from a depth of 3. This also means that the leftmost node and subtree of depth 3 runs Alpha Beta Sequential.
In sum, Principal Variation Splitting (PVS) is relatively efficient because we can perform a tree run at depth 7 in less than 7 seconds as we saw in the chess competition.
Evaluation
There are two ways of looking at the evaluation of a chess position. One can either, return the score relative to the next player who will play or consider that the white player is the player who will always be maximized.
In our case, we chose the second option. Thus, a score of 3.45 indicates a definite advantage for white while a score of -4000 indicates that black has a large advantage. We understand that a score of 0 indicates the beginning of a game, a tie or a position judged balanced by the evaluation function.
Material Evaluation
For the most simplistic evaluation, the relative value of the chess pieces is used. Initially, they were defined as follows:
- Pawn : 1
- Knight : 3
- Bishop : 3
- Rook : 5
- Queen : 9
However, they are not representative enough of the reality. A bishop, for example, is considered very slightly superior to a knight. Here are more accurate values, multiplied by 100 to fit the Piece Square Tables (see below):
- Pawn : 100
- Knight: 315
- Bishop : 320
- Rook : 500
- Queen : 900
Now, if we subtract from the sum of the values of the pieces of the white side, the sum of the values of the pieces of the black side, we obtain a first evaluation.
We understand that this simplified vision of the reality of the board is not sufficient to play chess correctly. Our evaluation function should also take into account the position of the pieces.
Piece Square Tables
In order to take into account the position of the pieces in the evaluation, tables have been created for each piece associating a value to each square. For each of the following tables, the blacks are located at the top and the whites at the bottom. Thus, the values are associated with the point of view of the whites.
private static final short[] PawnTable =
new short[]
{
0, 0, 0, 0, 0, 0, 0, 0,
50, 50, 50, 50, 50, 50, 50, 50,
10, 10, 20, 30, 30, 20, 10, 10,
5, 5, 10, 27, 27, 10, 5, 5,
0, 0, 0, 25, 25, 0, 0, 0,
5, -5, -10, 0, 0, -10, -5, 5,
5, 10, 10,-25,-25, 10, 10, 5,
0, 0, 0, 0, 0, 0, 0, 0
};
In the case of the above pawn, you can see on the second row of the white pieces (the second to last one in the Java board), the -25 values of the two central pawns will push the AI to prioritize the development of these. Indeed, if the two pawns remain in this position indefinitely, White will see 50 points subtracted from his score. Moreover, if the two pawns reach the squares d4 or e4, they will each receive a bonus of 25.
Also, we can notice that the more the pawns advance in the game, the more we try to reward them so that they can reach the last row and thus promote themselves.
In the case of the knight below, the central squares are rewarded while the ones near the edges have malus, because since the knight moves in an “L” shape, his possibilities are largely limited when he is not towards the center of the board.
private static final short[] KnightTable =
new short[]
{
-50,-40,-30,-30,-30,-30,-40,-50,
-40,-20, 0, 0, 0, 0, -20,-40,
-30, 0, 10, 15, 15, 10, 0, -30,
-30, 5, 15, 20, 20, 15, 5, -30,
-30, 0, 15, 20, 20, 15, 0, -30,
-30, 5, 10, 15, 15, 10, 5, -30,
-40,-20, 0, 5, 5, 0, -20,-40,
-50,-40,-20,-30,-30,-20,-40,-50,
};
Thus, now, in addition to the material value of each piece, we add a score associated with the position. In this way, the development of the pieces and the control of the center of the game is favored. Nevertheless, the values contained in the tables are general values intended to be used throughout the game. However, they may change. Indeed, if we take the example of the king, it is certainly preferable to keep it in the background during the opening and the middle of the game, but as soon as we enter the endgame, it becomes much more interesting to move it towards the center.
Tapered Evaluation
It is to solve this problem that the Tapered Evaluation was thought. It allows to modulate the values of some boards and pieces according to the phase of the game in which one is.
As the game progresses, a phase value is calculated, which is a number between 1 and 256 that indicates how close the game is to the end. Two evaluation scores are then taken into account (1) the opening score of the game (2) the score at the end of the game.
In this way, the final evaluation of a position will vary according to the phase of the game in which you are.
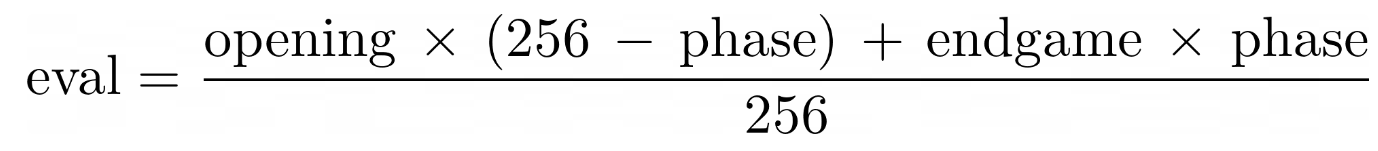
Where opening corresponds to the evaluation of the position with the instructions of the beginning of the game and ending that of the end of the game.
In the case of the King for example, here is his positional table at the end of the game:
private static final short[] KingEndingTable =
new short[]
{
-50, -40, -30,-20,-20,-30,-40, -50,
-30, -20, -10, 0, 0, -10, -20, -30,
-30, -10, 20, 30, 30, 20, -10, -30,
-30, -10, 30, 40, 40, 30, -10, -30,
-30, -10, 30, 40, 40, 30, -10, -30,
-30, -10, 20, 30, 30, 20, -10, -30,
-30, -30, 0, 0, 0, 0, -30, -30,
-50, -30,-30,-30,-30,-30, -30, -50
};
We can notice that the central squares are very valued. Indeed, when we enter the endgame, it is more optimal for the king to be in the center to cover all his pieces than to stay behind his line of pieces where he could be checkmated more easily.
Finally, we also have a bonus and penalty system depending on the phase of play and the number of pieces on the board. There is a penalty of -10 when the number of knights on the board is greater than 1 and a penalty of -20 when there is more than one rook in play or when there are no pawns in play. Also, there is a bonus or penalty for knights, bishops and rooks depending on the number of pawns.
private static final int[]
ROOK_PAWN_ADJUSTMENT =
{25, 20, 15, 10, 5, 0, -5, -10, -15};
Here for the rooks for example, when there are 0 pawns in play we assign 25 bonus points for the number of rooks in play because they can probably move better. On the contrary, if there are 8 pieces in play, then we give a 15 point malus per turn because the board is probably still too full for them to be used properly.
Optimizations
The optimizations listed below allow our AI to give its best shot in a minimum of time.
Move Ordering
The sorting of moves is certainly the most important optimization in our AI. Indeed, if we succeed in giving the Alpha Beta algorithm the best move first to evaluate, then it will be able to prune a very large number of branches and thus accelerate its computing capacity.
We have implemented the following sort:
- If the move is a capture, we return the value of the attacked piece
- If the move is a promotion, we return the value of the piece after the promotion
- Otherwise we return the value of the new position of the piece with the help of the Piece Square Tables
Thus, by sorting the moves after the generation according to the score associated with it, we promote the pruning of more branches of the exploration tree.
Opening Book
The opening is a very important phase in a chess game. It conditions the development of the pieces and the security of the king for the continuation. Thus, the use of opening books in more advanced chess AI is almost mandatory.
The software Polyglot is a very well known software in this field, in particular thanks to its binary format to represent an opening. Indeed, it presents important advantages, in particular concerning the saving of space, speed of access and research. Each position is stored as a hash value (8 bytes) and some additional information such as the number of times it has occurred, the number of games won by white/black/null with this position, the average/maximum ELO of the players playing this opening position, the success of the chess program with the position To save space, this additional information is usually 2 to 8 bytes.
Reading such a file is not very simplistic. For this we used the code of Alberto Alonso Ruibal whom we thank.
In our case, our book of openings contains about 20 000 played games. To save time, from a given position, we have always chosen to take the first move found in the book because it is the most played move.
Transposition Table
The chess tree can be seen as a graph, where transpositions may lead to subtrees that may have already been examined. A table of transpositions can be used to detect these cases and thus avoid duplicating work.
In some positions, such as king+pawn endgames with blocked pawns, the number of transpositions is so high that transposition detection is such a fantastic aid that huge search depths can be reached in seconds.
For implementation, the transposition table is in the form of an hashmap where an element is a pair of <key, node>. The key that indexes the hashmap is a special key, it is a Zobrist key. It is a simplified representation of a 64 bits game position. But 64 bits are not enough to represent completely a chess position, so we take the risk to have some collisions during the search. This value is calculated automatically by chesslib during the game.
For the node, it is a simple class which contains 3 attributes. The value of the evaluated position, the depth at which it was evaluated and its type. Indeed, with the alpha-beta search, we rarely find the exact value since we remove important parts of the tree. So we have an approximate value of the position, we just know that it is sufficiently better than another. It is therefore necessary to keep in mind the type of evaluation thanks to the type of the node.
There are 3 different types:
- Exact node : the value of the node was exactly the one we have
- Alpha node : the value of the node was at most the one we have
- Beta node : the value of the node was at least equal to the one we have
In this way, if we add the table of transpositions to the alpha-beta search, we will first look to see if the position has been evaluated before. In which case, rather than evaluating it again, we will update the final evaluation or the alpha and beta values according to the type of node stored in the table. Otherwise, we will add a new entry to the table when we reach a leaf in the game tree.
Despite the perfect appearance of this solution, it has some problems. Indeed, it is unimaginable to store all the evaluations since the beginning of the game. We would then lose all the interest of this optimization. We can then limit the size of the table and delete the oldest data when we reach the maximum size.
We did not keep this solution for the chess tournament because we did not experiment with it. Moreover, with the current implementation of our transposition table, the gain was not significant enough to increase the exploration depth of the tree.
Results
Perft
Performance test, move path enumeration or PERFT is a debugging function which allows to check the veracity of the generation of moves of a chess AI. It will count the number of leaves in the tree at a certain depth. Based on reference values we can check that everything works correctly. Also, by measuring the time elapsed for each iteration, it is possible to compare the performance of one move generation with another.
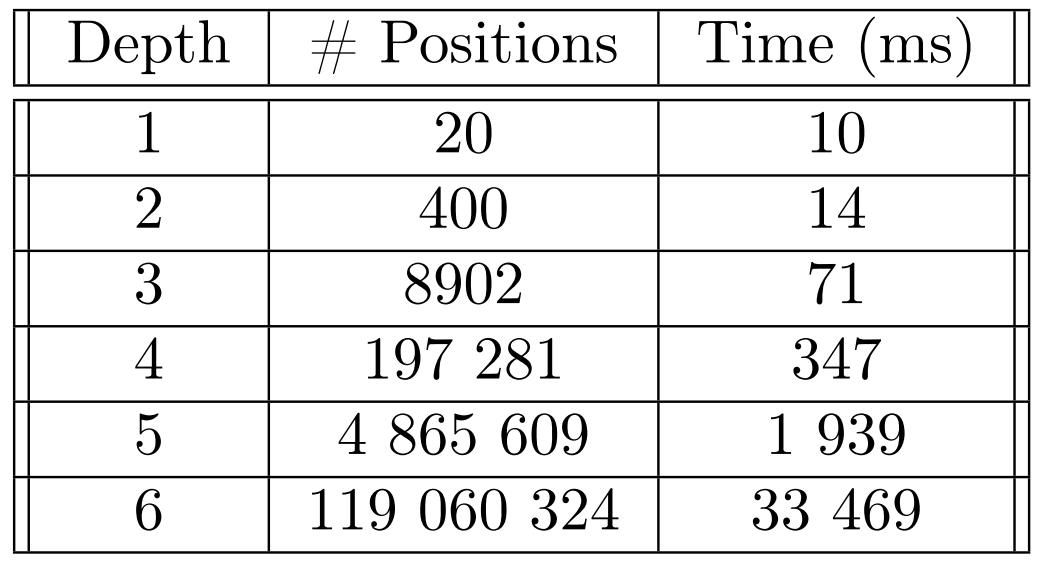
As can be seen above, from depths 5 and 6, the number of nodes and the elapsed time grow enormously. Moreover, we have checked and our values correspond well to the reference values.
Chess.com
To evaluate the ELO of an artificial intelligence in chess, there are computer chess rating lists maintained by groups of enthusiasts who play AIs against each other. To evaluate ours, we would have to play it against a large number of them to rank it. However, this is a complicated process to set up. Instead, we played our AI on chess.com to get an idea of its ELO.
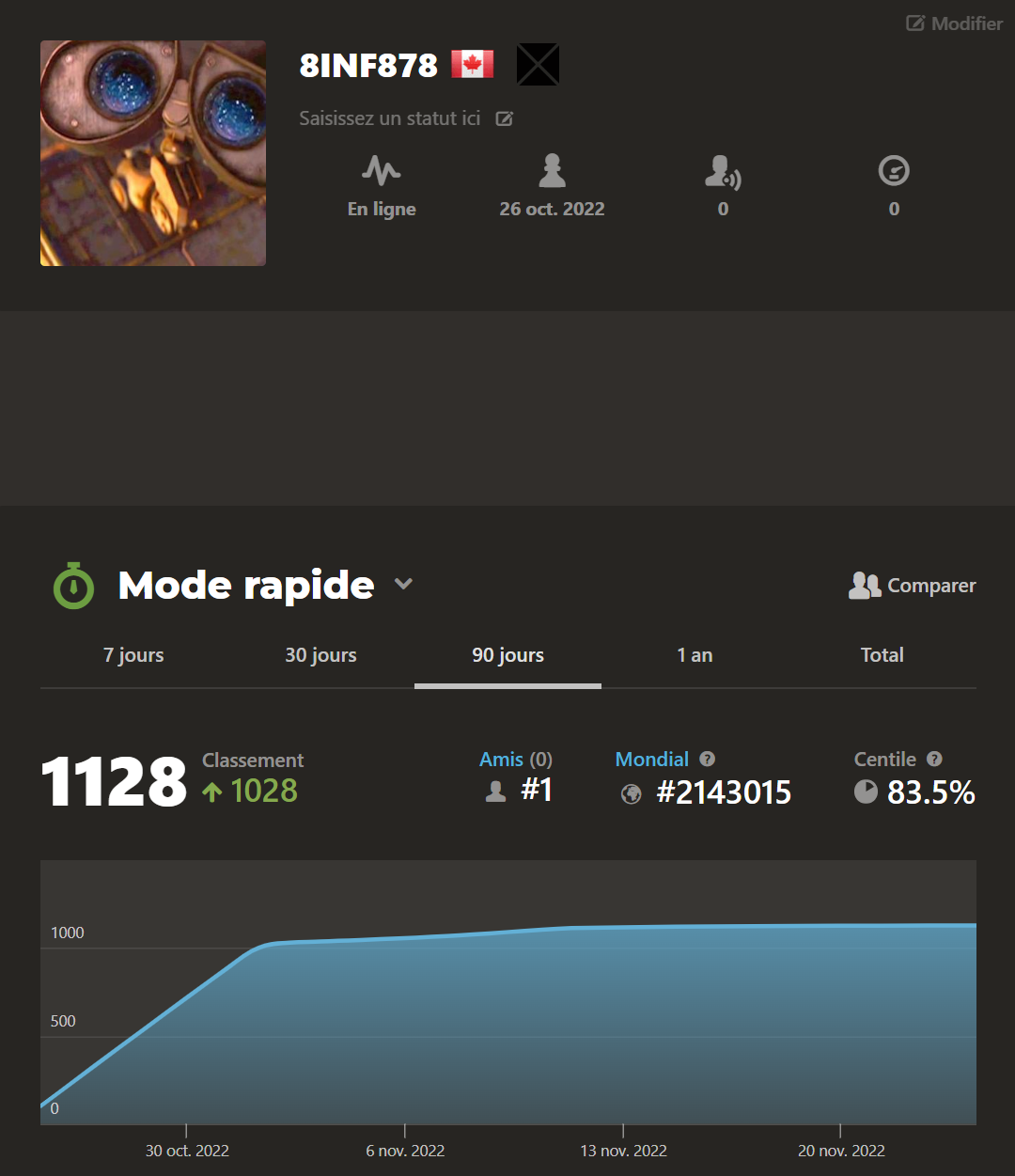
As you can see, we reached a final ELO of 1128. Which for a human player is an average ELO. In our case, we were quite satisfied with the result, as it is a good demonstration of the consistency of our AI over a fairly large sample of games (108).
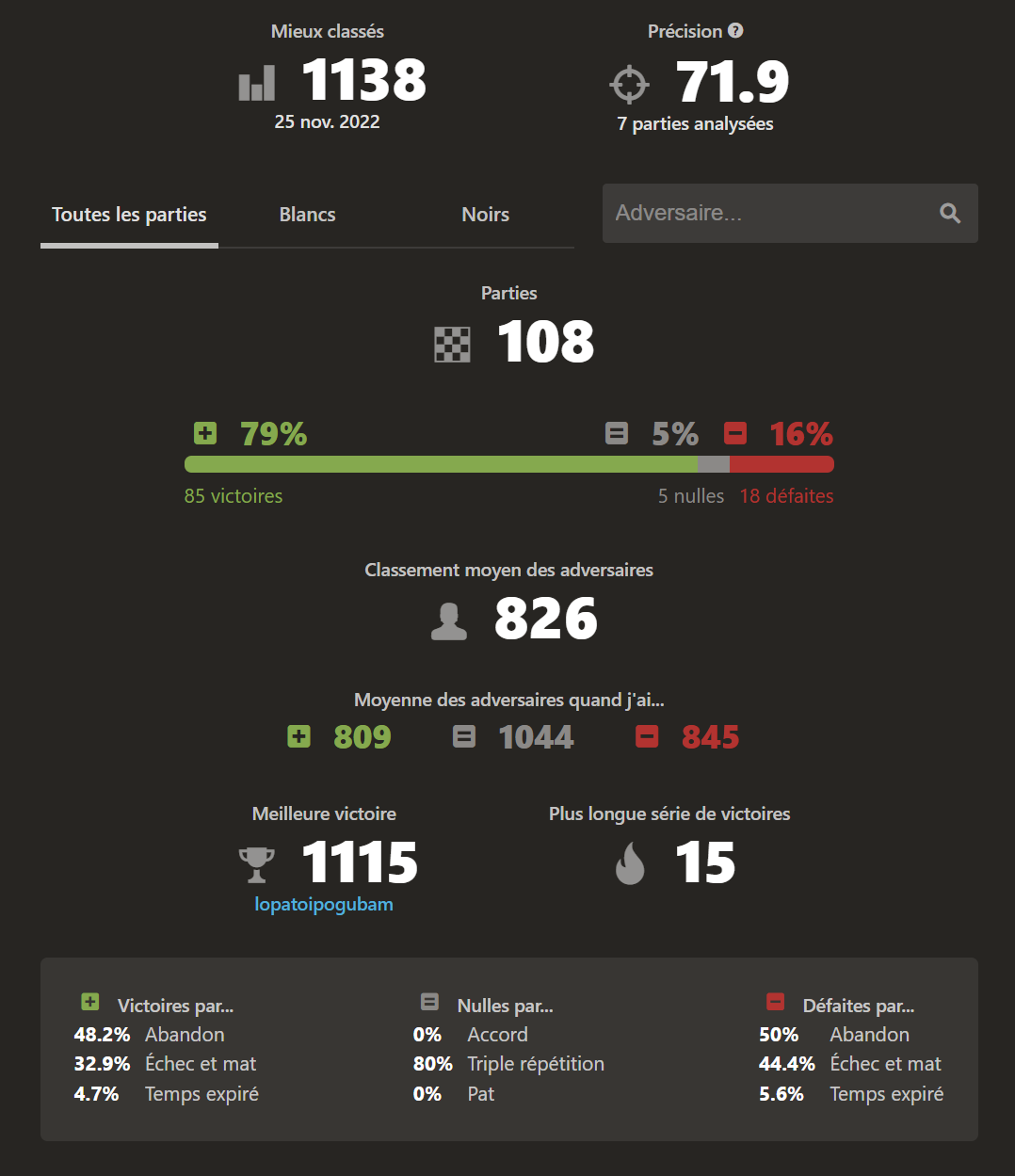
In more details, you can see that our AI has an average accuracy (on 7 analyzed games) of 71,9 %. This is a measure given by chess.com by comparing our moves to Stockfish’s. The more similar our move selection is, the more our accuracy increases. Also, you can see among the 16% of defeats, 50 % were caused by a dropout on our part. Indeed, since we had to manually reproduce the state of the game on Arena, the slightest error forced us to give up directly.
This experiment allowed us to see the limits of our AI. Indeed, in some situations, it did not want to move the game, because the evaluation function told it that this penalized its position. So it would play a piece, then return it to its initial square, etc. The human player could exploit this flaw and try to draw by repeating the same position 3 times in a row. Also, it made us realize the real problem of the horizon effect. In particular at the end of the game, if we had increased the depth of the tree to 7, our AI would have found mate directly, but being limited to 5, was playing moves without much interest.
You can find the profile of our AI here. In order to evaluate its real level for the tournament day, we always made it play in 1 second at a depth of 5.
Conclusion
In conclusion, we were able to experiment with the design of an intelligent agent for the game of chess. To do so, we first implemented simple algorithms and then we looked for optimizations to perfect the movements of our agent and optimize its performances. Moreover, we were able to demonstrate the interest of parallelization with our PVS algorithm distributed on different threads.
The condition of returning the best move in 1 second pushed us to optimize our code as much as possible in order to avoid all useless operations. As we developed the agent, we realized how much we were in an endless loop. Indeed, resources concerning chess AI are abundant on the Internet. So, if we had had 2 more months, we could have spent all that time improving each part of our agent with more advanced optimizations.
At this point, there are obviously still some imperfections in our agent, but at this stage, it is necessary to have a good knowledge of failures to realize the present problems. This is a positive point in our team, because one of us had a good theoretical knowledge of chess, which made it easier to judge quickly whether the changes made to the AI improved its level or not. At this level of detail, it becomes increasingly difficult to see the impact of modifications and one solution can fix one specific case and break 200 others.
Used Software and Libraries
- Programming languages: Java
- Libraries: Chesslib
- Source control: GitHub
References
[1] Khondker Hasan and al. « Implementation of a Distributed Chess Playing Software System Using Principal Variation Splitting. » In : jan. 2010, p. 92- 96.