Bias Mitigation in LLMs
This project was conceived as part of the “Practical Workshop in Artificial Intelligence II” course at UQAC, in collaboration with Martin Blanckaert, Valentin Porchet, Thomas Sirvent and under the supervision of Darine Ameyed and Riadh Ben Chaabene.
The objective was to produce a proof of concept in 2 months on a research topic of our choice. The choice of this subject was motivated by the recent explosion in popularity of large language models, which has highlighted inherent biases against certain demographics or cultures induced by training data. Not only does this shortcoming spread stereotypes and preconceived ideas, but data generated by LLMs is now being used to train new LLMs - which is obviously a dubious cycle. With this work, we hope to contribute to the existing research on the correction of these biases, which could lead to the development of more ethical and responsible models, as well as to highlight a problem that is easier to solve today than tomorrow.
Research Question
As for any research project, we started with an extensive literature review. Current research presents not only techniques for mitigating biases, but also for evaluating them - a critical step for addressing them. However, we spotted a major limitation in existing works : the techniques presented were tested on relatively small LLMs such as BERT or GPT-2, but rarely on billion-parameter models. We decided to angle our research around replicating bias mitigation experiments that seemed relevant - as well as reproducible - on large language models with billions of parameters. This led to the definition of the following research question :
Is fine-tuning on a specialized dataset (e.g. CrowS-Pairs) to reduce various biases in language models - proven effective on models such as BERT or GPT-2 - still effective on newer and larger language models (e.g. Bloomz or FLAN-T5) ?
We selected Bloomz and Flan-T5 because smaller versions of the models were available on HuggingFace, with respectively 560 and 248 million parameters. Although this contradicts part of our question, it was necessary to address the hardware limitations we were facing. This restriction was the most hindering we faced, having large needs (enough GPU RAM to fit a whole LLM in order to fine-tune it) with very low resources, the most we had being free-tier Kaggle Notebooks containing two T4 GPUs. Both these models are also capable of following task instructions zero-shot, a requirement to fine-tune them.
Evaluating Bias
To evaluate the bias in the models, we used two different types of metrics : three of them were provided by HuggingFace (Toxicity, HONEST, Regard), and three of them were our adaptations of metrics we found in the literature based on the StereoSet benchmark. StereoSet is a crowd-sourced dataset that captures four different types of biases. By prompting the model to select completions for sentences among offered ones - with some containing biases - we can calculate three scores representing not only the bias but also the general understanding of the model (Language Modeling Score, Stereotype Score, Idealized Context Association Test).
Finally, we needed a dataset to fine-tune the models. We selected the CrowS-Pairs dataset, which offers pairs of stereotyped and non-stereotyped sentences with the pairs usually differing on a single word that completely reverses the expected stereotype. Our approach involves either exposing the models to biased sentences or offering the sentences with a gap on the biased word, and then presenting the preferred responses as reference answers.
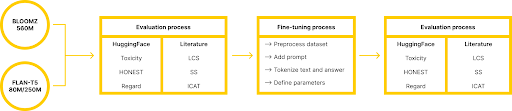
Results
Before fine-tuning, the FLAN-T5 family of models performed best in the StereoSet benchmark, showcasing superior reasoning abilities. However, the fine-tuning resulted in a decrease in overall performance, potentially due to the models not being specifically trained for rewriting sentences in a less offensive way. We experienced this problem with both models, struggling to prompt them in a way they were trained on. Additionally, we also encountered another phenomenon we learned about during our review of literature : catastrophic forgetting. This causes the models to completely forget their original training tasks after the fine-tuning. Existing research puts forward techniques such as freezing certain layers to mitigate this phenomenon, but those techniques were not reproducible. The HuggingFace metrics confirmed the decline in performance, with increased toxicity evaluations after fine-tuning. This increase also highlighted another limitation we read about, that states that reducing the capability of a model reduces its bias. This raises a question in the method we used : is the fine-tuning mitigating the bias or only reducing the model’s capability.
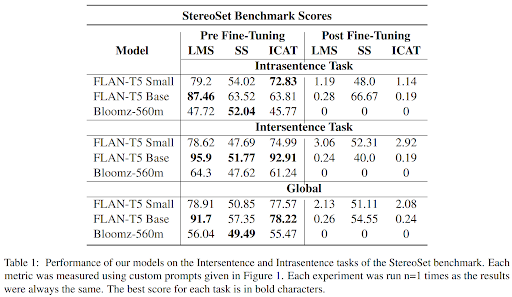
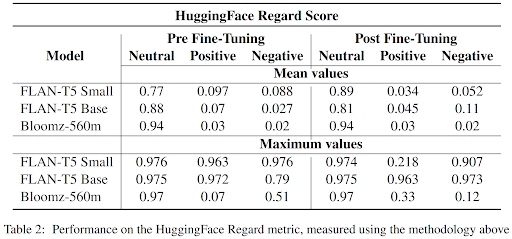
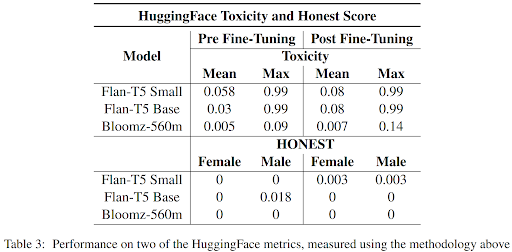
Conclusion
While our results were not as conclusive as we anticipated, they offered valuable insights. Firstly, it is clear that using small-sized models had a significant impact on various aspects, from text generation to instruction comprehension. This often led to models generating new sentences instead of completing the given prompts as intended. Secondly, our main approach of fine-tuning aimed to shift the tendency of the models to use certain words. While it may be viable for an effective change in behavior, it is not sufficient for creating a properly debiased LLM. In fact, it may inadvertently introduce biases in the opposite direction of existing stereotypes, which is not desirable.
Being used to completing projects and having access to documentation to solve problems, the lack of existing solutions to our problems was frustrating. Additionally, the hardware constraints we faced forced us to use smaller - which often means worse when referring to LLMS - models, resulting in lackluster results to our research. However, this project allowed us to verify and validate theories that had been put forward by other researchers, as well as to do our part in making AI models more responsible. We hope that our contributions will help in this endeavor and give future works a better idea of the challenges they will have to face.
Used Software and Libraries
- Programming language: Python
- Libraries : Hugging Face, Plotly
- Source control: GitHub
- Other tools: Jupyter, Overleaf